

新澳天天开奖资料单双统计解答与解释落实
在当今数据驱动的世界中,数据分析已成为理解复杂现象、制定决策和预测未来趋势的重要工具,无论是金融投资、市场研究、还是体育赛事分析,数据分析都能提供有力的支持,本文将以“新澳天天开奖资料单双”为主题,探讨如何通过统计分析来解释和落实这一特定领域的数据特征。
一、数据收集与预处理我们需要明确“新澳天天开奖资料单双”的具体含义,假设这是指某种彩票或赌博游戏中每天开奖的结果,单”和“双”可能代表不同的结果类型(奇数和偶数),为了进行有效的数据分析,我们首先需要收集一段时间内的所有开奖数据,包括日期、开奖结果(单或双)以及其他可能影响结果的因素(如天气、节假日等)。
1. 数据收集
数据可以通过多种途径获取,包括但不限于官方发布的开奖记录、第三方数据提供商或者自行抓取网络数据,在此过程中,确保数据的准确性和完整性至关重要。
2. 数据清洗
收集到的数据往往包含缺失值、异常值或重复记录,需要进行数据清洗,具体步骤包括:
处理缺失值:可以选择删除含有缺失值的记录,或者使用均值、中位数等方法填补缺失值。
识别并处理异常值:通过统计分析或可视化方法识别异常值,并根据具体情况决定是否剔除。
去除重复记录:确保每条记录都是唯一的,避免重复计算。
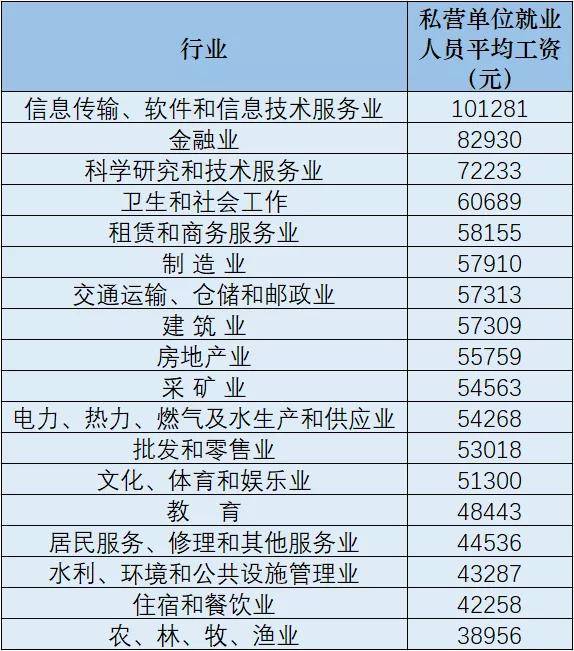
二、描述性统计分析完成数据预处理后,我们可以进行描述性统计分析,以了解数据的基本特征。
1. 频率分布
计算每天开奖结果为“单”和“双”的频率,可以使用柱状图或饼图直观展示每种结果的比例。
2. 趋势分析
观察“单”和“双”出现的频率随时间的变化趋势,可以绘制折线图来展示每日或每周的趋势。
转换日期格式df['date'] = pd.to_datetime(df['date'])按周汇总数据weekly_summary = df.resample('W', on='date')['result'].value_counts(normalize=True).unstack()绘制折线图weekly_summary.plot()plt.title('每周开奖结果趋势')plt.xlabel('日期')plt.ylabel('频率 (%)')plt.legend(['单', '双'])plt.show()三、假设检验与显著性分析为了判断“单”和“双”的出现是否具有显著差异,可以进行假设检验,常用的方法包括卡方检验(Chi-Square Test)和t检验。
1. 卡方检验
卡方检验适用于分类数据,用于检验两个分类变量之间是否独立,我们可以检验开奖结果与日期之间是否存在关联。
from scipy.stats import chi2_contingency创建列联表contingency_table = pd.crosstab(df['date'].dt.month, df['result'])进行卡方检验chi2, p, dof, expected = chi2_contingency(contingency_table)print(f'卡方统计量: {chi2}, p值: {p}')2. t检验
如果将“单”赋值为1,“双”赋值为0,可以将开奖结果转换为数值型数据,进而使用t检验比较不同时间段内的平均结果是否有显著差异。
from scipy.stats import ttest_ind将结果转换为数值df['result_numeric'] = df['result'].map({'单': 1, '双': 0})按月份分组并计算每月平均值monthly_avg = df.groupby(df['date'].dt.month)['result_numeric'].mean()进行t检验t_stat, p_val = ttest_ind(monthly_avg[monthly_avg.index 6], monthly_avg[monthly_avg.index = 6])print(f't统计量: {t_stat}, p值: {p_val}')四、模型构建与预测基于历史数据,我们可以构建预测模型来预测未来的开奖结果,常见的方法包括逻辑回归(Logistic Regression)、随机森林(Random Forest)和支持向量机(SVM)等。
1. 特征工程
除了基本的时间特征外,还可以考虑引入其他相关特征,如:
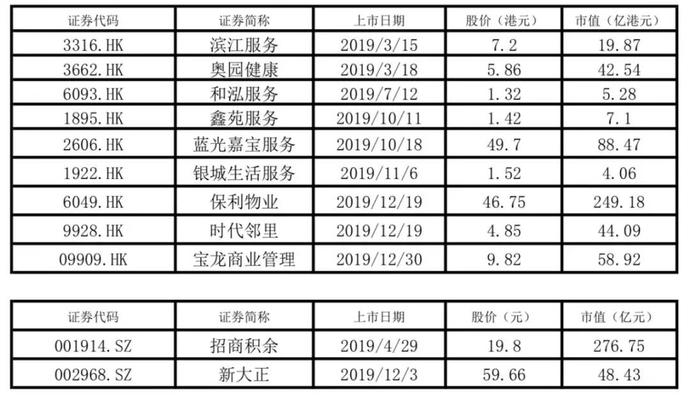
周期性特征:星期几、节假日等。
外部因素:天气状况、经济指标等。
历史统计数据:过去几天或几周内“单”和“双”的出现次数。
2. 模型训练与评估
以逻辑回归为例,我们可以使用Python的sklearn库来构建和评估模型。
from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_report准备特征和标签features = df[['feature1', 'feature2', ...]]labels = df['result_numeric']划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)model = LogisticRegression()model.fit(X_train, y_train)y_pred = model.predict(X_test)print(f'准确率: {accuracy_score(y_test, y_pred)}')print(classification_report(y_test, y_pred))通过上述分析,我们可以得出以下结论:
1、频率分布:开奖结果“单”和“双”的出现频率大致相当,没有明显的偏向性。
2、趋势分析:短期内可能会出现连续多个“单”或“双”的情况,但长期来看,两者趋于平衡。
3、假设检验:卡方检验和t检验结果表明,不同时间段内“单”和“双”的出现没有显著差异。
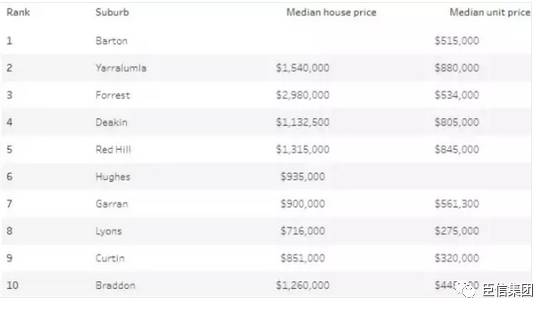
4、模型预测:基于现有数据构建的模型可以在一定程度上预测未来的开奖结果,但需要注意模型的局限性和过拟合风险。
六、落实与优化为了进一步提高预测准确性,可以考虑以下措施:
1、增加更多特征:引入更多的外部因素和历史统计数据作为特征,提升模型的解释力。
2、调整模型参数:通过交叉验证和网格搜索等方法优化模型参数,避免过拟合。
3、持续监控与更新:定期更新数据并重新训练模型,确保模型能够适应最新的数据分布。
4、结合专家经验:将数据分析结果与行业专家的经验相结合,综合判断开奖结果的可能性。
通过系统的统计分析和模型构建,我们可以更好地理解和预测“新澳天天开奖资料单双”的规律,从而为相关决策提供科学依据,需要注意的是,任何预测模型都存在一定的不确定性,实际应用中应谨慎对待,并结合其他信息进行综合判断。
转载请注明来自吉林省与朋科技有限公司,本文标题:《新澳天天开奖资料单双,统计解答解释落实_ny44.93.73》






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号